Introduction¶
What is StructuredData ?¶
StructuredData is a concept of organizing and storing your data and a software package for managing this data.
The concept¶
What kind of data can be stored ?¶
StructuredData supports simple data types like booleans, integers, floating point numbers and strings. It also supports lists and maps. A list contains simple data types or references of lists and maps. A map is an associative array where strings are associated with simple data types or references to lists and maps. Lists and maps can be referred to at more than one place in the data structure. Here is a diagram of a simple example:
In the diagram maps are displayed as round-edged boxes, lists are regular boxes, values are circles or squares.
Each arrow shows the relation between nodes, the small boxes above the arrows show the names of map keys or indices in a list.
Here is the same data displayed with the SDview tool:
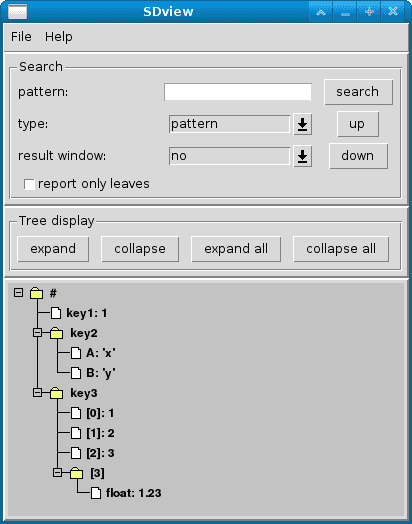
How is the data stored ?¶
The data is always stored in a file in YAML format. Here is an example how the data from the picture above together with type declarations is represented in a file. The pure data is the part between the labels “**SDC-Store**” and “**SDC-Types**”:
'**SDC-Metadata**':
version: '1.0'
'**SDC-Store**':
key1: 1
key2:
A: x
B: y
key3:
- 1
- 2
- 3
- float: 1.23
'**SDC-Types**':
'#':
struct:
- key1
- key2
- key3
'*.key1': integer
'*.key2':
optional_struct:
- A
- B
- C
'*.key2.*': string
'*.key3': list
See also StructuredDataStore and StructuredDataTypes for further explanations.
How do I address parts of the data ?¶
You use paths. A path is a string that is constructed after certain rules. In a list you address an element with an index, a number equal or bigger than 0. In a map you address an element with it’s key which is a string. When you have a hierarchy of Maps, lists and simple types, you can address each part in the structure with a list of keys and indices. A path is simply a concatenation of these, here is an example “domain[2].facility.description”. See “paths” for a detailed description.
How can I test the validity of the data ?¶
StructuredData supports type declarations for all or parts of the data. The type information can be stored in the same file as the data or in a different file. You can specify the all types mentioned above, booleans, integers, floating point numbers, strings, lists and maps. For lists you can specify that all elements must have one simple type. For maps you can specify that the keys must be from a set of allowed keys, that all keys of a set must be present among others or that exactly the keys of a set must be present. The concept of paths allows you to have incomplete type declarations if you choose so. The python library, SDpyshell and SDxmlrpc have commands in order to check if the data is compliant to the type declarations. More details on type declarations can be found here: StructuredDataTypes.
The software package¶
What does it do ?¶
The software package is a set of libraries and programs written in python. The three main applications are the SDpyshell, SDxmlrpc and SDview.
SDpyshell provides interactive access for exploring and changing the data. This is python with extra StructuredDataTypes commands, so you can write scripts in SDpyshell. It can also be used in server mode where clients can connect via telnet.
SDxmlrpc provides access to the data with a set of XML-RPC functions. Through this you can access the data with all programming languages which have an XML-RPC client library. Such languages are for example python, perl, ruby, c, c++, and java.
SDview is a program with a graphical user interface that is used to display and perform queries in the data.
Do I always have to use the software package ?¶
You don’t have to. StructuredData files are YAML files. You can view and edit these files directly with your favourite editor. There also exist many implementations for YAML in various programming languages, for example python, perl, ruby, c, c++ and java.
Applications of StructuredData¶
Where can StructuredData be useful ?¶
StructuredData can be used to store configuration data for programs and applications. It can replace XML files. It can replace relational or non-relational databases if it is possible to load the complete set of your data in your computer’s memory.
How does StructuredData support collaboration ?¶
StructuredData is file based with a merge and diff friendly text format (YAML). For read only access for several people you can use the SDpyshell in server mode or the SDxmlrpc server. For write access for several people you should use StructuredData together with a version control system, e.g. mercurial . In this case a user gets a working copy from your central data store where he can apply modifications e.g. by using SDpyshell with the local copy. He can then use the version control system to put these changes to the central data store where they can be merged with changes from other users.
Can graphs be represented in StructuredData ?¶
They can. Each item in a list or map that is another list or map is in fact just a reference. So you can reference the same list or map at several places in your data structure. By this you can represent directed graphs in StructuredData, even cycles in that graph are allowed.
Can trees be represented in StructuredData ?¶
Since trees are a special case of directed graphs, they can.
Can the data of a relational database represented in StructuredData ?¶
It can. Each table can be represented as a list of maps. Each map contains the column names as keys and the values of one row as values for these keys. There is no need for primary keys since we have references in StructuredData. Foreign keys in tables can be replaced with references to the rows in the references table. Types of columns can be converted to StructuredData type declarations. You can also enforce a fixed set of column names with StructuredData type declarations.
Comparisons to other concepts¶
Advantages of StructuredData compared to a database¶
Since StructuredData is file based on a human readable text format, the data file can easily be managed with a version control system. If you develop in a team, you can use the branch and merge mechanisms provided there. You can easily visualize differences between two StructuredData files with tools like tkdiff or kompare.
Since the StructuredData file format is YAML, you can easily browse and modify the file in any text editor. It is not necessary for you to learn a query language. If you don’t want to use SDpyshell you don’t have to. You can use SDpyshell just for the typecheck, which is a simple single command.
Since the StructuredData file format is YAML, you can read it directly in your favorite programming language.
Due to the hierarchical organization of the data there is no need for primary or foreign keys like in relational databases. If you want to create relations between different parts in the hierarchy you can link them since StructuredData may contain links and YAML can represent links.
If you include type declarations in your YAML file every user is free to modify everything but type declarations will prevent you from making mistakes like spelling errors. If you choose to put type declarations in an extra file, not modifiable by all users, you can fine-tune what the users may change and what they may not change. This is much more flexible than the table scheme of a relational database where you very rarely change or add tables and you usually don’t have the rights to do this.
Advantages of StructuredData compared to other text file formats¶
Since StructuredData organizes your data hierarchical, it is very flexible. Probably all other file formats can be represented in StructuredData. It is for example very easy to convert csv data to StructuredData. Even structures of hashes, lists and scalars in perl or structures of dictionaries, lists and simple immutable values in python can be converted to StructuredData.
Since the StructuredData file uses the YAML format, you can read it directly in your favorite programming language. This is an advantage compared to custom file formats where you have to implement the parser libraries yourself.
The sequence of items in a StructuredData file is well defined. Two sets of StructuredData that are the same are guaranteed to have the same file representation. If you add new values, each new value is in a new line on it’s own, this makes StructuredData merge friendly with respect to version control systems.
StructuredData has a shell, SDpyshell, that can be used interactively or scripted to browse, export, import or modify the data.
Changes of many parameters in a StructuredData file are easy by the capability of SDpyshell to export, import and merge data.